13 рецептов создания AI-ассистента для музыкального театра: от онбординга до классификатора
Ключевые показатели проекта
- Пользователи: 50 родителей + 50 детей + 10 преподавателей
- Обработка: 10-12 млн токенов/месяц
- Платформа: n8n + Grok, DeepSeek, Claude Sonnet (в качестве консультанта и кодера)
CRM vs ССМ
Рецепт 1. Никаких интерфейсов с кнопками
В итоге родился меморандум для родителей:
1. Ванесса - не смотря на то, что отправляет смайлики - программа для Telegram бота - робот.
2. Администрация читает все диалоги, ИТ служба постоянно редактирует поведение Ванессы.
Рецепт 2. Онбординг
Короткий диалог с пользователем, чтобы он не чувствовал что его игнорируют

В принципе, можно автоматизировать сопоставление пользователя и его TelegramID, но я не стал заморачиваться и вношу ID ручками. В инструментах у Агента - документ FAQ - то есть, в процессе входа в нашу CCM, пользователь может получить ответы на все вопросы про театр. Просто, легко в реализации и работает - редкое сочетание.
Рецепт 3. PID настройки моделей
Несколько лет занимаюсь FPV. Первый навык пилота - собрать и настроить дрон. Физика в дронах реализована PID регуляторами, настройками которых можно регулировать поведение железки в очень широком диапазоне от валенка до сгоревших моторов. В LLM есть похожие параметры, проставляются в параметрах чат-моделей. Например, DeepSeek дает такую табличку для Температуры:
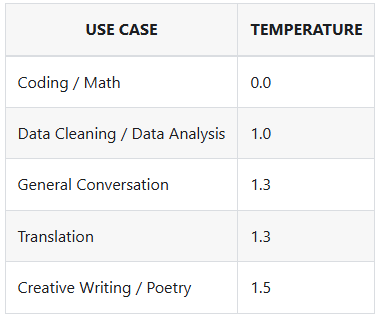
Есть еще штрафы, размер ответа. Регулируя параметры можно заставить модель генерить инференс нужного вида. На рисунке 3 настройки моделей слева - для общения с новенькими, справа - парсер платежных документов.
Однозначно, эту приправу следует добавлять для качества и вкуса. Правила применения - надо изучать отдельно. Я поставил значения интуитивно.
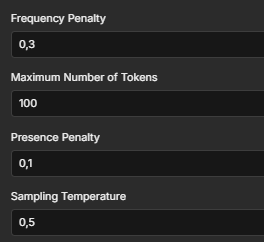
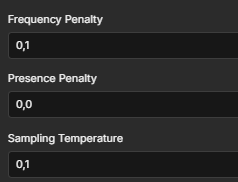
Рецепт 4. База данных
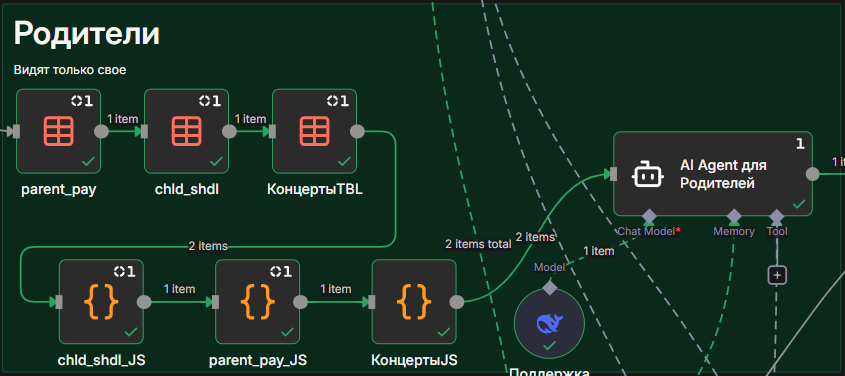
Как я говорил в предыдущей статье, база данных - файл в Google Sheets. Этот файл удобно править, создавать новые листы с расписанием, в нем подсчитываются начисления и долги. Создать аналог Google Sheets - сломать все кости. Но есть нюанс: обращение к Google Sheets, с одной стороны - время (3-10 секунд на запрос), с другой - у креденшиала для Google есть ограничение на частоту обращений. Решение — периодическая синхронизация. Каждый час данные из Google Sheets копируются во внутреннюю структуру n8n — DataTables.
DataTables - реализация на базе какой-то простой СУБД, но она хорошо интегрирована с остальными узлами N8N, хоть и самобытна. Сначала было дико осознавать отсутствие функционала реляционности, но потом принял, что реляции можно делать через JS.
На рисунке 4 Воркфлоу обновления базы данных из Google Sheets. Она обновляется раз в час по расписанию, или вебхуком, который дергает инструмент AI-Агента Админа. Иногда, ну очень нужно срочно обновить те правки что внесены в Эксель.
Архитектура n8n гениальна в своей простоте: все узлы работают с JSON. Они принимают JSON на входе и возвращают JSON на выходе. Поэтому, в общем случае, можно забрать таблицу Google Sheets и передать ее в DataTables (как это сделано с костюмами), а можно обработать узлом CODE на JS и распределить по нескольким таблицам (как это сделано с родителями и детьми).

Рецепт 5. Бухгалтер
Этот рецепт мне особо нравится! Родители делают 60-80 платежей в месяц. Такое количество является небольшим с точки зрения того, чтобы ручками разнести по экселю, но! громадным когда что-то потерял и надо найти.
В промптах Ванессы есть несколько вставок о том, что оплатил - пришли квитанцию. Дальше я стандартными инструментами беру файл, выделяю текст из PDF и бросаю агенту с задачей выделить: ФИО, номер документа, сумму, адресата, дату. Планировал скрупулезно сопоставлять поля документов, но решил попробовать AI-агента — решение оказалось правильным. Очень порадовался, когда увидел что народ кидает в виде чеков.
В какой-то момент, увидел ругань родителя с Ванессой - вот же, оплатил, почему не учла? Оказалось - родитель кидает в чат скриншот из приложения сбера с большой зеленой галочкой.
-
Хоботов, я оценила!!! - подумал я.
И сделал цепочку, объясняющую что нужен PDF (на рисунке блок Что за док). Чудо, но проблема пропала. Естественный интеллект очень хорошо настраивает диалог с искусственным.

Рецепт 6. Заранее подготовьте продукты
Инструменты в AI-Агента - это волшебство! Пишешь в промпте какой инструмент что делает, в каких случаях вызывается и штука работает. Было ощущение того, что получая данные через инструменты, получится сократить количество сжигаемых токенов. Но возникли проблемы:
-
Обращение к инструменту - это, минимум, еще один заход в LLM, чаще два и более - токены утекают.
-
Не всегда Агент обращается к инструменту, каких промптов с угрозами ему не пиши. А если не сходил в инструмент - нет данных - выдумка здравствуйте.
Поэтому все блоки я переделал вот в таком сценарии: получили данные, JS сделали фильтры и маски, чтобы не передавать в LLM служебные поля а-ля id, дата создания, дата обновления. В промпт добавляю заклинание в виде:
# ДАННЫЕ и контекст
##Расписание
Структура:
- dayofWeek - День недели
- date - Дата занятия
- time - Время занятия
- weeknumber - Номер недели
- subject - Предмет/направление
- group - Название группы
- teacher - ФИО преподавателя
- notes - Заметки и комментарии если меняется место занятий, то тут новое место
- childrenname - ФИО ребенка
важно если в notes есть упоминания нового места занятий - эти данные приоритетны
Данные о расписании формате JSON
{{ JSON.stringify($('chld_shdl_JS').all().map(item => item.json), null, 2) }}
И снова есть нюанс: в данном случае он в количестве данных. Таблички до 10 строк смело добавляем в системный промпт, если больше - появляется U эффект. Например, грубо, если загнать список из 35 должников, то по запросу о долгах будет возвращаться рандомно от 30 до 35 человек. Серединку LLM “забывает”. По началу, было странно.
Рецепт 7. Закрывайте крышку
Не сразу, но в какой-то момент осознал то, что для LLM null и “нет данных” - две большие разницы в результате. Вся вероятностная суть LLM со штрафами за поведение прямо заставляет ее выдумывать там, где пустота. Выдумка в расписании и платежах - сильно напрягает всех. Поэтому, следует явно указывать ситуации где нет данных:
{{ $('parent_pay_JS').all().length > 0 &&
$('parent_pay_JS').all()[0].json.data &&
$('parent_pay_JS').all()[0].json.data.length > 0 &&
Object.keys($('parent_pay_JS').all()[0].json.data[0]).length > 0
? JSON.stringify($('parent_pay_JS').all().map(item => item.json), null, 2)
: 'Платежей нет' }}
За код не ругайте. Очень примерно понимаю что тут происходит - код генерирует Sonnet.
Рецепт 8. Страховка обязательна
Весь мир LLM непривычно хрупок. Все, начиная с оплаты виртуальными картами, сбоев VPN, смены структуры API (как это сделала команда DeepSeek 1 декабря, изменив свой reasoner) приводит к непонятному и неприятному молчанию Агентов или к ошибкам. В AI-Агентах есть галочка Использовать FallBack Model, соответственно - эта опция обязательна!
Для себя выбрал Grok и DeepSeek-chat в качестве FallBack. Но тут креатив приветствуется.

Рецепт 9. Персонификация
Когда начал общаться с директорами театров и студий, услышал термин “служба заботы”. То, что, для влетающих в предметную область на крыльях ИТ, выглядит как “административная единица”, на самом деле важный человек на стыке между родителями и процессами. Поэтому, интуитивное решение дать боту имя и фото, оказалось очень даже удачным решением.
# Роль
Административный помощник Обнинского Музыкального Театра. Имя - Ванесса Ираклиевна.
Родитель знает, что общается с ИИ, но он также знает, что за всеми переписками следит человек и голосом Ванессы может дать ответ - в какой-то момент граница стирается.
Рецепт 10. Логи. Читайте логи!
Логи - концепция очевидная. Однако, в данном случае, логируя всю переписку в отдельный Telegram канал, я читаю диалоги людей и ИИ. И именно диалоги, вопрос - ответ, позволяют файн тюнить поведение Ванессы. Например, в какой-то момент пришло осознание, что отмененные занятия идут сплошным списком с обычными и есть шанс пропустить. Строчка в промпт.

Рецепт 11. Делай как я!
“Чтобы найти грибы, нужно думать как гриб!”
Наши мыслительные процессы и процессы построения инференса в LLM очень похожи. Учитесь думать как LLM. Сначала это непривычно, но со временем начинаешь понимать, откуда берутся ошибки в промптах.
Исходя из того, что LLM всегда выбирает наиболее вероятный следующий токен, для получения нужного результата повышайте в промпте вероятность того, что вам нужно получить на выходе.
Техники, в том числе, такие:
-
Использование текст
-
Использование терминов, которыми прошит промпт. Лучше термины из двух и более слов. Так вы сдвигаете направление вектора инференса в Вашем, специфическом, мире, уменьшая, тем самым, влияние мирового знания на Ваш результат.
-
Использование [ ]. Это высший пилотаж и сильно зависит от LLM. Где-то содержание скобок - библейские термины, например, в SUNO. В других LLM - необязательный параметр.
-
Примеры. Пример - вообще отличная техника. А пример и антипример - просто супер.
Вот такая, казалось бы простая, конструкция, с неимоверной вероятностью, выдаст все числа, касающиеся денег, с разбивкой по разрядам жирным шрифтом.
Пример:
ПРАВИЛЬНО:
Кредиторка на ближайший месяц 1 234 876 рублей
НЕ ПРАВИЛЬНО. ОШИБКА:
Кредиторка на ближайший месяц 1234876 рублей
Рецепт 12. Безопасность
Telegram, как и web - дикие джунгли. На аватар Ванессы сразу прибежали поклонники. Обязательно следует фильтровать пользователей. Я делаю это по Telegram ID. Все кто не мои - утыкаются в бесконечный диалог с простым AI-Агентом Онбординга и очень быстро теряют интерес к флирту.
Рецепт со звездочкой. Молекулярная кухня
Для тех кто дочитал до этого места и понимает что происходит. Классическая физика ИТ проекта - если зашел, то будет расти. Соответственно, в архитектуре следует предусмотреть этот рост, который, скорее всего, не заложен в ТЗ и прочих исходных идеях.
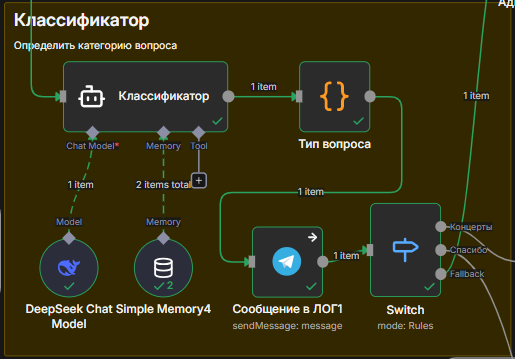
Сначала я разбил функционал по типам пользователей: Админы, Родители, Дети, Новенькие. Но, когда появилась задача помощи с Концертами, решил на входе поставить классификатор по типам вопросов, чтобы делать AI-агентов не длинным промптом с кучей инструментов, а решать короткие простые задачи. Плюсов огромное количество:
-
Промпт не раздувается, за ним легче следить и нет склероза
-
По вопросу пользователя вызывается короткий промпт, который сжигает меньше токенов и отрабатывает быстрее и точнее.
-
Новая задача - отдельный простой промпт.
Но есть и минусы:
-
Классификатор съедает 800 токенов на каждый запрос
-
Не всегда из вопроса пользователя понятна тема, пришлось какое-то время налаживать процесс классификации
-
Возможна ситуация, когда классификатор отравил не тому агенту. Пользователь влетает в Агента, в котором нет знаний по нужной теме. Например: расписание концертов и расписание занятий - разные агенты, и бывает в расписание занятий влетает вопрос о концертах. Поэтому в “смежных” AI-агентах есть закладки из соседа. Например: вот расписание, но есть еще и такие-то концерты, хотите расскажу? Ответ пользователя в виде “ДА” полетит уже в другого AI-Агента.
Однако, если разобрались в кухне и наладили классификатор, то, например, в ответ на Спасибо от пользователя мы идем не в большой промпт, сжигающий до 15К токенов Grok, а в отдельный AI-агент, который стоит 280 токенов DeepSeek-chat.
Заключение
Лет 10 назад у меня родилась мысль о том, что было бы классно поместить какие-то специфические знания в специальные программки. Хозяйство большое: начиная с клубники на огороде и заканчивая задачами по работе, которые 5 раз объяснил, но потом все обнулились, а сам забыл. Я завидовал программистам, которые могут собрать на Pyton приложение, вычисляющее по видео котов и шугающее их с грядок автополивом.
Произошел квантовый переход - появился оркестр инструментов, которые можно освоить, они не вываливаются из рук и не разбегаются. Получается сделать то, что очень хотел, но требуемая энергия была просто запредельной. Причем, главный в этом оркестре не N8N, а Sonnet.
Ванесса уже “кругленькая” - занимается родителями и все счастливы. В работе RAG по документации, Феликс Эдмундович (раньше работал в спецслужбах) для контроля финансов, логистики и склада.
Есть мысль попробовать поставить Ванессу еще в несколько театрально-музыкальных коллективов, однако осознание ее самобытной специфичности пока не дает сделать шаги по коммерческой дорожке. Но первое что я сделаю - перенесу Ванессу на локальную LLM, чтобы не выдумывать схемы с анонимизацией










-
Кому принадлежит Grok?
-
Как работает Grok?
-
Является ли Grok точным?
-
Может ли Grok помочь с конкретными задачами или вопросами?
-
Является ли Grok бесплатным сервисом?
-
Можно ли использовать Grok на мобильных устройствах?
-
Доступен ли Grok на разных языках?
-
Как начать работу с Grok?
Что такое Grok
- Grok — это нейросеть, созданная компанией xAI Илона Маска. Её можно назвать прямым конкурентом ChatGPT от OpenAI.
Войти в Grok
- Появление революционного искусственного интеллекта, способного коренным образом изменить наше настоящее и сформировать контуры будущего. Grok от xAI
Регистрация Grok в России
- Grok — это современная нейросеть от компании xAI (Илона Маска), которая отличается прямым, иногда провокационным и юмористическим стилем общения. В